年末なのでAPIを利用してNSX-Tをお掃除しよう
この記事は2021年の vExperts Advent Calendar の23日目の記事です。
前日は MT9276さんの VMware HOLで、Apache Log4j のワークアラウンド手順確認(PythonスクリプトをHOLへ持ち込み) でした。 スクリプトを持ち込めるのは自分も初めて知りました! HOLでWAを試せるとなると、複数回試すことができて、実際のWA適用の際に安心できるな、と思いました。
ものすごいいまさらですが、2021年からvExpertになりました、@yaaamaaaguuu です。
ブログやTwitterではあまり言及しませんが、普段はNSXの運用や検証, NSXを利用するソフトウェアの開発などに取り組んでいます。
せっかくなのでNSX-Tに関する記事でvExpertアドベントカレンダーの1記事を担当させていただきます。よろしくお願いいたします。
年末も近いので、大掃除をしないといけない気持ちになってきますね?
この記事では、NSX-TのAPIを利用して、検証等などで作ってしまった不要なリソースを消していく方法を紹介し、年末の大掃除でUIをひたすらポチポチし続ける苦行を回避する方法を共有しようと思います。
目次
注意書き
NSX-T上のオブジェクトを削除するAPIを取り扱います。削除APIをコールすると当然対象のリソースは削除されますので、対象を誤らないように気を付けてください。誤ったAPIコールで、誤ったオブジェクトを削除してしまっても私は責任をとれません。
また本記事は NSX-T 3.1系とLinux上で動作するコマンド (zsh, curl, jq 等)を利用した記事となります。
さらにVMC上のNSX-Tについての差異は扱いません。
NSX-TのAPIについて
2021/12/22 時点での最新のNSX-Tのバージョンは3.2.0となり、APIドキュメントは こちら となります。(基本的にはAPIドキュメントに記載されている内容の抜粋となります。)
何はともあれ、NSX-TのAPIをコールできないことには話が始まりません。とりあえずAPIをコールするにしても、認証情報を付与する必要がありますが、NSX-T上のユーザー名/パスワードをBasic認証の情報として付与してあげるとよいだけです。以下のようなコマンドになると思います。
# 試しにNSXのClusterの情報を参照してみる
curl -k -u "${username}:${password}" https://${NSXMANAGER}/api/v1/cluster/status
JSON形式でNSXのClusterの情報が出力されたら成功です。以降のAPIコールが上手くいかない場合は、利用してるユーザーの権限を確認してみるとよいと思います。(clusterのステータスの表示が上手くいかなくても、消したいと考えているオブジェクトを消す権限などがある可能性もあると思いますし、その逆もあると思います。)
APIコールが上手くいったならば、次に削除対象のオブジェクトを指定する方法を探します。
Full text search API
NSX-T の各個別API (例えば、セグメントを参照する GET /policy/api/v1/infra/segments など) には、細かい条件 (例えば表示名が HOGE で始まるなど) を指定する方法がありません。その代わりに Full text search API が備わっていて、こちらのAPIを利用すると、参照するオブジェクトをある程度細かく指定することができます。
このFull text search APIを利用するパスは2個あります。これは、Policy Planeのオブジェクトか、Management Planeでのオブジェクトか、を意識して使い分ける必要があります。APIドキュメント内の Searchable types には両方が記載されていますが、パスによって参照可能なオブジェクトが異なったりします。(Management PlaneのオブジェクトとPolicy Planeオブジェクトに関する詳細は別途NSX-Tのリソースを参照してください。)
GET /policy/api/v1/search/query- Policy Planeのオブジェクト用APIパス
GET /api/v1/search/query- Management Planeのオブジェクト用のAPIパス
APIパスについてをなんとなく把握したら、次はFull text search APIで利用するQuery Syntaxについてです。とはいっても、こちらのSyntaxについてもあるドキュメント程度詳細に記載されているので要点だけ記載します。
- Query Syntax 要点
ということで、簡単な例を記載しておきます。
# NSX-T上のグループ かつ 表示名の先頭がYAMAGUCHI_ となっているモノ
curl -k -u "${username}:${password}" -k -G --data-urlencode 'query=resource_type:Group AND display_name:YAMAGUCHI_*' 'https://${NSXMANAGER}/policy/api/v1/search'
あとは、上記の要領で、必要となるオブジェクトを検索するクエリを作り上げます。
オブジェクトを削除していく
ここまで来たらあとは、大した手間ではありません。 resource_typeで削除対象としたいオブジェクトを指定しつつ、各個別のオブジェクトの削除APIをたたいていくとよいです。 APIレスポンスからうまく削除対象のidを引き出すためにjqなどと合わせながら以下のようなスクリプトを組みます。(jqがよくわからなければ、 https://stedolan.github.io/jq/manual/ あたりのマニュアルを眺めるとよいです。)
# 例えばYAMAGUCHI_とPrefixのついたグループを片っ端から削除する
for groupId in `curl -k -u "${username}:${password}" -G --data-urlencode 'query=resource_type:Group AND display_name:YAMAGUCHI_*' 'https://${NSXMANAGER}/policy/api/v1/search' | jq '.results[].id' -r`;
do
echo curl -k -X DELETE 'https://${NSXMANAGER}/policy/api/v1/infra/domains/default/groups/'$id;
curl -u "${username}:${password}" -k -X DELETE 'https://${NSXMANAGER}/policy/api/v1/infra/domains/default/groups/'$id;
sleep 1;
done
まとめ
NSX-T のAPI + jq + shell script で NSX-T上のオブジェクトを一括で削除する方法を記載しました。
NSX-T上のお掃除はAPIをうまく利用してサッとやって年末を迎えましょう。
この記事は2021年の vExperts Advent Calendar の23日目の記事でした。
明日は、Yuki Kawamitsuさんがストレージ関連で何かの記事を投稿するとのことです。お楽しみに!
備忘録: Kinesis AdvantageでF1~F10のふるまいを元に戻す
https://kinesis-ergo.com/wp-content/uploads/kb500-user_manual.pdf を見るとよいのだけども = + w を押すと元のF1~F12に戻る。
( = + m を押すと、マルチメディアグループ機能というやつが有効になって、F10とかF11あたりを押すとボリュームのアップダウンになる。)
マルチメディアグループが有効になっていると、IDEを使っているときのF1 ~ F12 を交えたショートカットが軒並みダメになってめちゃくちゃ不便。
ロードバランサー 入門準備
この記事は富士通クラウドテクノロジーズ Advent Calendar 2020の24日目の記事です。
23日目は id:foobaron さんの EVPN L2VPN All-Active MultihomingにおけるRoute Typeと経路迂回 でした。 データセンターのネットワーク運用者は要チェックです。
25日目は inasato さんの 「ESXi Arm Edition v1.1 で物理 NIC の追加してみた」 です。
アドベントカレンダー24日目の記事です。12/24といえばクリスマスイブです。どんなプレゼントがもらえるか?がワクワクする日ですね。インフラエンジニアならば誰しもがクリスマスにロードバランサーをプレゼントされるのを夢見たことがあるのではないかと思っています。
クリスマスとは関係ないですが、ロードバランサーを触る機会をいただくことが年々増えているため、一度ロードバランサーの入門前に知っておきたかった話 (もしくは一度知ってしまえばなるほどね。と思えるような話) をまとめておこうと思います。いろいろなことを書こうとは思いますが、LBに精通しているわけではないので抜け漏れはあると思います。
以下の文章でロードバランサーはLBと省略し、以下のようなことを記載します。
- LBに期待されることの説明
- LBの論理構成とその時に関わる用語や方式など
- LBのよくある設定項目とその補足
- LBを検証するに当たって用いると良い検証ツールの紹介
- LBを知るに当たって参考となる資料
以下のようなことは本記事では記載しません。
- 特定のLBが備える機能の詳細
- LBを用いた負荷試験などの計画や実施方法
- LBを運用する際に必要な考慮点
- etc
LBに期待されること/LBで実現できること
基本的にはある1つの宛先に対する通信を受け取った際に、設定した複数の宛先に振り分けることがLBには期待されます。例えば1度目の192.0.2.1に対する通信を192.0.2.11に、2度目の192.0.2.1に対する通信を192.0.2.12に振り分ける、といった振る舞いを期待します。ユースケースとしては複数台用意した同一のwebアプリケーションサーバーに通信を振り分けること実現します。
1つの宛先を複数の宛先に振り分ける都合上、複数の宛先が宛先として機能するか?を確認し、宛先として機能しない場合は宛先としては見なさない様にすることもLBには期待されます。具体的な例を挙げると、LBから一定の間隔で振り分け先のIPに対してICMPでの通信を試みて、複数回の返信がなければ振り分け先のサーバーから除外する様な振る舞いを期待します。ICMPは具体例の一つで、試みる通信のプロトコルや試みる頻度が選択可能であることも期待されます。通信の振り分け先が全て不能の状態だと判定した際にはLBがエラーのページをレスポンスすることも期待されます。
また、LBはクライアントとコンテンツをレスポンスするサーバーの中間に位置する都合、複数の振り分け先で処理するよりも中間のLBで処理してしまった方が良いことを処理することも求められます。よく挙げられる例としては、SSL/TLSの通信の終端や、特定の通信を許可/拒否するフィルタリングですが、解釈するプロトコルがより高レベルなものだと、認証認可のための処理を挟むことができたりします。
最後に、LBは、ある宛先に対する通信を1度集約し、分散させる装置である都合上、LB自身に可用性が期待されます。具体的には, 2台以上の同様なLBでActive/Stanbyの構成や、Active/Activeの構成が取れることを期待されます。また1台のLBに障害が発生した際にも、既存の通信に与える影響を最小に通信の処理を継続できることが求められます。
LBとネットワーク構成など
ここではLBのネットワーク構成などについて言及しようと思います。 物理的な話や論理的な話での分類というよりは、対比しやすい話を記載していきます。
アイコンと図の説明
以降いくつかアイコンを用いた図を使いますが、以下のようなイメージで使い分けています。また黒い線はネットワーク的な繋がりを、オレンジ色の線は通信の経路を示すつもりで利用しています。
イメージをつかむ足がかりになることを目的としているので、正確な構成図は示しません。
また特にロードバランサーのアイコンは後述するLB装置/バーチャルサーバー/LBインスタンスとしてのアイコンを特に使い分けていません。話の文脈的にLB装置であるか、バーチャルサーバーであるか、LBインスタンスであるか?を識別するのが重要なときだけどのような役割でLBアイコンを使っているか記載します。

バーチャルサーバー
LBと一口に言っても、物理的なハードウェアを利用して実現する方法や、仮想サーバー上のOSにソフトウェアをインストールして実現する方法などあります。
物理ハードウェアや仮想サーバーなど複数のLBのための装置を1セットのLBとみなした時、更にそのLBの中で複数のロードバランスの設定を持つことができるケースが多いです。LB装置内部に仮想的なサーバーを持つようなイメージでバーチャルサーバーと読んでいるようです。ここではバーチャルサーバーと書きましたが、この呼称はLB製品によってまちまちだと思います。
下記の図でLBのアイコンは、実際にパケットを処理しているプロセス的な何かだとイメージしてください。良い言葉が無いのでこの文章ではLBインスタンスと呼びます。
LB装置とバーチャルサーバーの設定と、LBインスタンスなどの組み合わせにより無限に考え方があると思うのでコレはあくまで一例です。
例えば、Active/Stanby構成のうち、片方のバーチャルサーバーの通信を処理するLBインスタンスのActive/Stanbyを入れ替えるとLB装置としてはActive/Active に見えたりすると思います。 (実際に通信を賄うのはどちらかになるので、バーチャルサーバーから見たらActive/Stanbyは変わらないですが。)
またLB装置が複数のケースでもそうで、バーチャルサーバーの設定の適用範囲や、その適用範囲のうちどのように通信を処理するLBインスタンスが稼働して通信をさばいたりは様々な組み合わせがあります。モノによって組める構成は異なると思うので要確認です。

VIP
バーチャルサーバーは通信を受け付けるIPを設定する必要があります。その通信を待ち受けるIPをVIP (ビップもしくはブイアイピイ)と呼びます。バーチャルサーバーのIP で Virtual IPとのことです。
2台構成, 複数構成
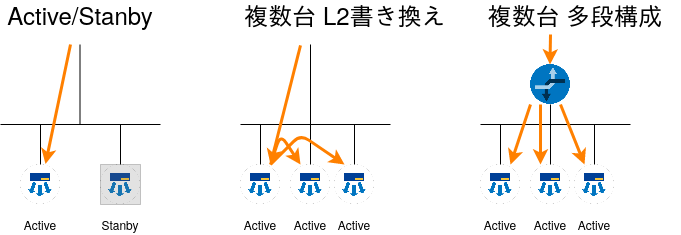
前述したようにLBには可用性が求められます。2台のLB装置でActive/Stanbyの構成を作り、Activeが障害を起こすとStanbyに切り替える構成をよく聞きます。またソフトウェアで実現するロードバランサーでは3台以上のLB装置を連携させる方式も聞きます。
特にソフトウェアベースのLBで3台以上を連携させるときに見かける方式としては、代表のノードが一度通信を受取、L2の宛先を書き換えて他のLB装置に転送する方式と、上位のルーターとBGPで連携し上位ルータの段階で複数のLB装置に通信を分散させる多段なロードバランサーを構成する方式を見かけます。
以下の図では振り分け先サーバーを省略していますが、オレンジ色の先が届いているActiveと記載されているLBから振り分け先に通信を転送することになります。
1arm, 2arm/インライン
続いてイメージしやすい話を記載すると、1arm, 2armインラインがあると思います。 1armは通信を受け付けたNICから振り分け先サーバーに通信を転送する構成で、2arm/インラインは通信を受け付けたNICとは異なるNICから振り分け先に通信を転送する構成になります。

ロードバランサーを介した通信の送信元IP
クライアントとクライアントからのリクエストを処理する間にロードバランサーが存在することになります。クライアントからロードバランサーがVIPで通信を受け付けた際に、送信元IPアドレスをロードバランサーが書き換えずに振り分け先にパケットを転送するのが透過IP(P透過, 透過モード)、 送信元IPアドレスをロードバランサーが設定されたIPに書き換えるのがSNAT (透過IPと対比して、非透過と呼ばれることもあるらしい) です。
また送信元IPを書き換えてしまうと、振り分け先サーバーでは本来の送信元が不明になります。そのための対策としてHTTPの通信をロードバランスする際にX-Forwarded-Forヘッダーにもともとの送信元IPを記載する機能や、HTTPも含めその他のプロトコルの際にも送信元がわかるようにProxy Protocolに対応する機能があったりします。
フローティングIP
Active機が故障し、Stanby機がActive機に昇格するような際に、Active側で待ち受けていたIPをStanby側に引き継ぐ必要があります。所有者が変わる必要があるさまを指してFloating IP と読んでいるみたいです。
個人的にはStackoverflowのこの解答 を読んでわかった気分になりました。
ロードバランサーのよくある設定項目/確認ポイント
複数のロードバランサー製品を見て共通で備わっている機能には以下のような項目があります。 この項目と、前述のネットワーク構成の設定を組み合わせてロードバランサーを実現することになります。
具体的な要件が決まっている設定値は、要件が満たされているか?を確認すると良いと思いますが、そうでない値はどのような機能があるかを眺めながら動作確認することになると思います。
- 振り分け可能なプロトコル
- 振り分け先選定
- どの様な振り分け先選定方法があるのか?を確認すると良いです。
- round robin や least connection などがありますが、正確なことは利用するLBのドキュメントを読むのが良いです。
- 振り分け先固定
- HTTP通信のセッションの保持の都合などで、1度アクセスしたサーバーにしばらく接続され続けるのが好ましいケースがあります。
- どのように振り分け先を固定することが可能かを把握すると良いと思います。
- また振り分けの固定がどれだけ持続するか?も確認すると良いと思います。
- ヘルスチェック
- ヘルスチェックの試行方法
- どのようなプロトコルでヘルスチェック可能か?
- ヘルスチェックの試行間隔はどれくらいか?
- ヘルスチェックの失敗判定の条件
- 1つの振り分け先が振り分け不可と判定する条件は何か?
- 1回の試行は何を満たすと失敗と判定されるか?
- ヘルスチェック失敗からの復帰条件
- 「ヘルスチェックが3回成功したら復帰と見なす」などの条件を見ると良いと思います。
- ヘルスチェックの試行方法
- エラーページについて
- どの様にエラーページを設定可能か?
- リダイレクト
- 固定ページの表示
- その他
- どの様にエラーページを設定可能か?
- フェイルオーバー時の挙動
- 求める要件によっても変わってくるので一例となります。
- ロードバランサー自体がどの様に障害を検知し、フェイルオーバーするか?
- 確認すべきポイントは構成に依存するので詳細は追わないです
- 障害検知までの時間, 障害検知から通信を処理する筐体の切り替わりまでの時間
- 障害の検知は早ければ早い方が良いですが、誤検知しない程度が求められます
- 既存の通信に対する影響
- 障害を検知したLBを介していた通信が、LBの切り替わり後も問題なく通信可能か
ロードバランサーを検証するに当たって用いると便利な検証ツールの紹介
検証をする際に利用すると便利なツールを雑多にいくつか紹介しておきます。これらのツールを用いて、前述の設定項目/機能が意図通り動作しているか?を確認していくことになると思います。
ここで上げるツールは基本的にLinuxで使えるものを挙げます。
- netcat
- The GNU Netcat -- Official homepage
- ncと呼ばれたりもします。
- netcat1つでTCP/UDPの擬似的なクライアントとしても、擬似的なサーバーとしても活用することができます。
- 例えば、shellとうまいこと組み合わせる事で擬似的なwebサーバーとしても動かすことが可能です。
- curl
- curl
- 特に自分から説明することがないくらいには有名なツールだと思いますが、一応
- nmap
- Nmap: the Network Mapper - Free Security Scanner
- ポートスキャニングのツールとしてよく挙げられます。
- ロードバランサーの検証としては特に、ssl-enum-chipers が便利です。
- どの暗号化方式に対応しているか?を一覧で見ることが可能です。
- TLS 1.3 には未対応なのでその点だけ注意です。
- tcpdump
- TCPDUMP/LIBPCAP public repository
- パケットキャプチャツールです。
- これも自分から特に説明することは無いと思います。
- Wireshark
- Wireshark · Go Deep.
- パケットを収集したり、収集したパケットを見やすく表示したりするツールです。
- ロードバランサーの検証をする際は、クライアント/ロードバランサー/振り分け先サーバーで取得したパケットをWiresharkで眺めることになると思います。
- NGINXとngx_http_perl_module
- Module ngx_http_perl_module
- webサーバーと、perlをもちいて動的なコンテンツを返すモジュールです。
- ngx_http_perl_moduleを推す理由は、多くの場合NGINXをインストールすると利用可能だからです。
- nginxと適当な言語のアプリケーションサーバーを組み合わせて… という様なことが得意であればそちらを使う方が良いと思います。
- 例えば、以下の様なことを実現したいケースで便利です。
- 振り分け先サーバーが認識した、送信元IPをレスポンスに記載する
- 振り分け先のサーバーのホスト名をレスポンスに記載する
- 振り分け先サーバーに届いたHTTP通信のX-Forwarded-Forのヘッダーの中身をレスポンスに記載する
- Fabric
- Welcome to Fabric! — Fabric documentation
- 複数のサーバーに対して、コマンドを実行することができるpython製のツールです。
- pythonのコードの中に、実行したいコマンドを記載する形式になります。
- 手軽に複数の振り分け先サーバーのセットアップ/設定変更する際に便利です。
- 使い慣れていればAnsibleなどでも良いと思います。
- Locust
- Apache JMeter
- Apache JMeter - Apache JMeter™
- こちらもHTTP/HTTPSのリクエストを多数飛ばすツールとなります。
- 先人たちがJMeterでパフォーマンス計測した結果が残っていたりするケースがあると思うので、使えて損がないと思います。
本記事の参考文献 もしくはLBを学習するに辺り参考になった文献
自分がLBを学ぶにあたっては、以下の資料が大変参考になりました。
書籍
- サーバ負荷分散入門
- 前半は負荷分散技術に関して書かれています。
- 後半はF5社のBIG-IPのLTMの仮想アプライアンスを利用したものとなっています。
- 書籍で扱っている内容はv11系列で、最新版はv16系のようです。
- 学習時に触っただけなのでBIG-IPのLTMに関しては全く詳しくないのでv11とv16系でどれだけ違うのか?不明です。
- 自分は後半を流し読みしてしまったので、BIG-IP v16系 でも書籍通り検証できるか?も不明です。
Web
まとめ
ロードバランサーの初歩的な話をまとめて記載しました。将来的に誰かの役に立てば幸いです。
この記事の図は https://app.diagrams.net/ と ニフクラ アイコン&シンボル を利用して記載しました。
この記事は富士通クラウドテクノロジーズ Advent Calendar 2020の24日目の記事です。
23日目は id:foobaron さんの EVPN L2VPN All-Active MultihomingにおけるRoute Typeと経路迂回 でした。
25日目は inasato さんの 「ESXi Arm Edition v1.1 で物理 NIC の追加してみた」 です。 Raspberry Piで実現できるESXi Armの欠点を克服しそうなネタなので楽しみですね。
Emacsで手動でhexを入力してバイナリを編集するための備忘録
Emacsで手動でhexを入力してバイナリを編集するための備忘録
例えば30日OS自作本などだと最初にhexを入力しましょう。みたいなのが出てくるのだけども、そういうのこそ使い慣れたEmacsでさっとやってしまいたい。
Emacsの標準のhexlモードだと人間がhex値を入力することでバイナリを編集するのは可能(C-M-x
実現されてほしいこと
- 0 を入力したら 0x00 の カーソルが当たっている桁が0になる
- 該当カーソルの値が 0x30 にならない。
- 末尾にhexが追記可能
- 末尾のhexが削除可能
準備
nhexl-mode をインストールする
M-x package install
編集
M-x nhexl-mode M-x nhexl-nibble-edit-mode
VMwareのデータセンター向け製品を個人で検証するためのTips
この記事は富士通クラウドテクノロジーズ Advent Calendar 2020の3日目の記事です。 id:yaaamaaaguuu が記事を書き、職場の先輩である id:hidemium さんからフィードバックを受けて加筆修正したものになります。(hidemiumさんありがとうございました。)
2日目はdaprでつくるマイクロサービスでした。daprが便利そうなことが伝わってくる記事でした。自分も後日試してみたいと思っています。
皆様にとって、2020年はどのような年だったでしょうか?
個人的には VCP-NV と呼ばれるVMwareの資格を取得するために色々と取り組んだことが心に残っています。
資格試験のためだけではないですが、自宅にVMware製品を導入した検証環境を構築してVMware製品を検証することが多かったため、そのまとめとして、VMwareのデータセンター向け製品を個人で検証するためのTipsを紹介することで、個人で検証するためのハードルを下げることができたら良いと思っています。
目次
- 目次
- 注意事項
- とにかく手早く設定方法などを確認したい
- とにかく物理で動くESXiを用意したい
- 物理環境でなくてもいいからESXiを用意したい
- 個人の検証環境にもvCenterやNSXを用意したい
- 複数の物理マシンを用意してvSphere + NSX + α を動かしたい
- vCenterをESXiにさっとデプロイしたい
- NSX Managerが起動できない もしくは NSX Managerを起動するとほかのVMが起動できない状況に対処する
- NSX-T のマネージャーでスナップショットをとりたい
- まとめ
注意事項
あくまで検証用途です。本番環境で今回紹介するTipsを適用すると、本番環境でサポートされなくなる可能性のある手法も含みます。筆者宅の検証環境などで試していることが大半ではありますが、試す際はご自身の責任でお願いいたします。
とにかく手早く設定方法などを確認したい
VMwareが用意しているHands on Labを利用しましょう。
利用したい製品がデプロイされるHoLを起動し、用意してあるトレーニングのメニューを無視して、 自分の確認したいことをさっと確認してみる、というのは新しい製品で検証環境が十分でないときに有効な手段です。
とにかく物理で動くESXiを用意したい
ESXiはMyVMwareに登録したらisoをダウンロードできたと思うので、そちらを利用すると良いです。
ネットワークの構成や性能にかかわらず、物理のESXiを用意したい場合は、IntelのNUCを購入しESXiをインストールするのが良いと思います。なぜIntelのNUCを推すかというと、William Lam 氏のブログ https://www.virtuallyghetto.com で頻繁に推されていて、 動作確認がされていることが多いからです。もし将来的にvSANなどを検証したい場合は2.5インチベイがあるほうを選ぶと良いです。
NUCなどを利用していてPCIeなどで物理NICを拡張することができない場合や、適当なコンピュータのマザーボードのNICがESXiに対応していない場合はこちらのDriveを導入してUSB NICをつかうことになります。USB NICは製品によってサポートされるMTUの上限が異なるポイントに注意してください。(自分が複数購入したものは4500程度でした。)
個人的には試せていないのですが、 (1台あたりの価格が通常のNUCよりだいぶ高価ですが) Intel NUC9 extreme を利用するとNICの構成の問題を解消できると思います。
またx86にこだわらない場合、Raspberry piなどで試せるESXi Arm Editionなどが選択肢に入ってくると思います。
物理ノードのリソースは、システム要件 (+お財布事情) に沿って用意していただくのが良いですが、vCenter,NSXの検証でCPUのリソースの実消費は比較的少ないのに対し、メモリの実消費は比較的多いことに注意する必要があります。
具体的な話をすると、筆者の検証環境は、core i3-6100U, 32GBのメモリのNUCが3台構成のところにvCenter/NSX-T Managerをデプロイ、HAとvSANを有効にしている状態で以下のようなリソース状況です。

本番環境では互換性のある物理サーバーを用意してください。
物理環境でなくてもいいからESXiを用意したい
物理のマシンにESXiをインストールする以外に、ESXiを仮想マシンとして用意する方法があります。ネステッド もしくは ネスト と呼ばれています。物理のESXiの上にNested ESXiをデプロイして、Nested ESXiの上に仮想マシンをデプロイして色々試すことが可能です。試したことはないですが、VMware のWorkstationやFusionで動作させる方法もあるようです。
Nested ESXi を用意するには2つ手法があります。
- ESXiのisoを利用して仮想マシンにインストールする
- William Lam 氏が公開しているNested ESXiのovaを利用する
上記の2つの方法のうち、前者に取り組むことは勉強にはなりますが、用意するのに割と手間がかかります。Lam氏の公開しているNested ESXiのイメージが非常に実用的なため、そちらを利用するとよいでしょう。ただし、公開されているovaのハードウェアバージョンが比較的新しいため、 場合によっては自分でisoから用意する必要があります。
Nested ESXi を稼働させるにはいくつか気をつけたほうが良いことがあります。
- https://kb.vmware.com/s/article/2009916?lang=ja にも記載がある通り、 Nested ESXiはサポートされないので、本番環境で利用しない方がよいと思います。
- Nested ESXIに与えるCPUやメモリは、ESXiのシステム要件に準拠すると良いのですが、NSXを動作させるためのESXiとしてNestedを利用する場合は、8GBのメモリは与えたほうが無難です。
- Nested ESXiが接続する仮想スイッチの設定については Why is Promiscuous Mode & Forged Transmits required for Nested ESXi? を読むと良いです。
- Nested ESXiをクローンする前に、How to properly clone a Nested ESXi VM? を読むと良いです。
個人の検証環境にもvCenterやNSXを用意したい
あくまで個人向けの検証用途の話です。
VMUGのAdvantage のライセンスを利用するのが良いと思います。値段は$200/year (2年継続だと $180/yer, 3年継続だと $170/year)だそうです。
2020/12/02 だと、vCenter, NSX-v, NSX-T, vSAN, Tanzu などに加えて、
VMware FusionやWrokstationのProなどがダウンロードできるライセンスとなっています。
前述のNUCなどにESXiをインストールするか、Fusion/Workstationで各アプライアンスを起動して検証する形になると思います。
複数の物理マシンを用意してvSphere + NSX + α を動かしたい
各種vSphereやNSXの機能の利便性を実感するには、複数のESXiがある方が良いケースが多くあります。そして複数のESXiを用意して検証をするには最低限スイッチとNASではないかと考えています。
- スイッチ
- EdgeRouter Xをスイッチとして採用している話をよく伺います。
- NAS
- SynologyかQNAPのNASを採用している話をよく伺います。
- vSphere のHA や vMotionを試すには必須です。
宅内検証環境の物理構成の詳細に言及し始めるとキリが無いので、この記事ではこの程度にとどめます。
vCenterをESXiにさっとデプロイしたい
vCenterをESXiにさっとデプロイするには、isoからGUIのインストーラーを起動するのが一般的ではあると思います。
ただ、vCenterをインストールする際のパラメーターは決まり切っているので、
検証の際に何度もいちいちGUIでパラメーターを埋めて...というのは面倒な気がします。
そんな時は、govc をつかって、vcsaのアプライアンスをデプロイすると良いです。
# iso をmountする, ディレクトリは適当 mount -t iso9660 VMware-VCSA-all.iso /mount_dir # iso 内のvcsaのovaからインポート用の情報を生成する govc import.spec /mount_dir/VMware-vCenter-Server-Appliance-xxxx_OVF10.ova | jq . > vcsa_import_spec.json # vcsa_import_spec.json を適切に編集する # guestinfo.cis.deployment.autoconfig = "True" にすると、 # vcsaを起動後にパラメーターに沿って自動的に設定してくれます。 # https://www.virtuallyghetto.com/2016/10/how-to-deploy-the-vcenter-server-appliance-vcsa-6-5-running-on-vmware-fusion-workstation.html が参考です。 # import.ova には適当にデータストアやデプロイ先を指定するオプションが必要です。 govc import.ova -options=vcsa_import_spec.json /mount_dir/VMware-vCenter-Server-Appliance-xxxx_OVF10.ova
こちらの方法はVMwareのドキュメントに記載があるものではないので、あくまでデプロイを簡易にする非公式手順であることに留意してほしいです。
NSX Managerが起動できない もしくは NSX Managerを起動するとほかのVMが起動できない状況に対処する
NSX-T Managerもovaをデプロイ直後はメモリのリソースの予約 (手元の環境で見ると16GBのメモリ) が入っています。検証環境のリソース状況によっては、NSX Managerが起動できないケースや、NSX Managerが起動できても他のVMが起動できなくなるなどが考えられます。
リソース不足起因のトラブルを踏まないようにするためには、検証環境のリソースを増強するのが良いのですが、暫定的にはNSX Managerのメモリの予約を外してしまうことでNSX Managerや他のVMが起動できなくなることを回避できます。
商用の環境でNSX-T Managerのリソースは予約は外さないでください。
NSX-T のマネージャーでスナップショットをとりたい
NSX-T Managerはスナップショットをサポートしていません。そのためにアプライアンスでスナップショットを無効にする方法 がドキュメントに記載されています。またNSX-T 3.0.1 以降ではスナップショットが取れなくなるための設定が予め入っています。
しかし、個人の検証レベルではサポートを受けられるか否かよりも、例えばテキトウにスナップショットを取ってアップデートを実施してみるなどの気軽さのほうが大事な気がします。ということで、ドキュメントに書いてあることに逆らうことにはなりますが、仮想マシン オプションから snapshot.MaxSnapshots を必要に応じて編集すると良いと思います。
まとめ
VMwareのデータセンター向け製品を個人で検証するためのTipsを記載しました。何かの参考になれば嬉しいです。
今回のTipsは個人向けということで、ドキュメントの互換性や手順などを、思いっきり無視しているモノとなります。
間違っても商用の環境で試すなどはしないでください。
この記事は富士通クラウドテクノロジーズ Advent Calendar 2020の3日目の記事でした。
明日の4日目はGit Hooksでうっかりミスを防ぎたいだそうです。gitのhookは非常に便利なのでどのような記事が投稿されるのか楽しみですね。
zabbix5.0でDockerの監視メモ
セットアップ
zabbixでDockerを監視するには、zabbix_agent2が必要なので、以下のドキュメントに記載されているOSをを利用すること。
zabbix serverのセットアップは以下に沿う。
agent2は、パッケージのセットアップまでは一緒で、インストールするパッケージが、zabbix_agent2だけで良い。
Dockerを監視する
以下の通り、 Template App Docker があるので、監視対象のhostに、Template App Docker を紐付けたら良い。
(なければ、zabbixのリポジトリからxmlが拾ってこれる。)
Templateを紐付けたのに監視が開始できないときは、監視対象のOS上で、zabbix agentを動かしているユーザーをdocker groupに所属させると良いはず。
また監視できる項目についても、以下のURLに詳細が記載されている。
動作確認について
監視対象のホストで以下のコマンドを叩く
zabbix_agent2 -t docker.ping -c /etc/zabbix/zabbix_agent2.conf
zabbix server が稼働するホストで以下のコマンドを叩く
(こちらがうまく行かないケースならば、 監視対象のホストでzabbix agentを動かしているユーザーをdocker groupに所属させると良いはず。)
zabbix_get -s ${target_ip} -k docker.info
ESXi 6.7 以降の vmxnet3 を利用している仮想マシンの上でTrexを動かす
要は、Trexが依存しているライブラリ等のバージョン問題の話なので、TrexがDPDK20.05を取り込んだら賞味期限切れの記事になります。
これの動作確認を試そうと思いましたが、ESXi 6.7 以降のvmxnet3では、2020/07/25時点でのlatestのTrex (v2.82) では動作しなかったので、動かせるようにするための記事です。
ESXi 6.7 以降の vmxnet3 を利用している仮想マシンの上でTrexなぜ動かないのか?
バージョンを記載しておくと、自分の手元の環境では、ESXi 7.0, Trex 2.82 の組み合わせで動いてません。
Trexというのは、DPDK を利用しています。このDPDKはDPDKに対応しているNICのドライバを持っています。
今日時点でのTrexはv2.82, Trexがベースとして利用しているDPDKのバージョンは20.02です。 DPDKの最新版は20.05みたいです。
vmxnet3 というのはESXiを利用しているとおなじみの仮想NICです。 vSphere 6.7 で vmxnet3 v4 というのがリリースされています。 (なので、記事のタイトルはESXi 6.7以降と書いています。)
問題点としては、(おそらく) DPDKがvmxnet3 v4 対応してからこのコミット (2020/03/08に取り込まれているので、多分DPDK20.05に入っている修正) までDPDK側にバグがあり、 DPDKが用意するドライバとNICを紐付けることができませんでした。
Trexのフォーラムなどでも投稿されています が以下のようなメッセージが発生し、Trexが起動しません。
./t-rex-64 -i ... vmxnet3_v4_rss_configure(): Set RSS fields (v4) failed: 1 vmxnet3_dev_start(): Failed to configure v4 RSS vmxnet3_dev_start(): Device activation: UNSUCCESSFUL
修正方法
要は、上記のcommitをTrexに適用して、ビルドできればOKです。
Trexのビルド方法はwikiに記載があるのでソレに従います。なるべく新し目のgccと、依存ライブラリをインストールしたうえで作業すると良いと思います。
$ mkdir /opt $ cd /opt $ git clone https://github.com/DPDK/dpdk.git $ cd dpdk $ git checkout 52ec00fd1474e8f99f3da705b7efe95ba994b352 $ git clone https://github.com/cisco-system-traffic-generator/trex-core.git -b v2.82 $ cd trex-core $ \cp -fa ../dpdk/drivers/net/vmxnet3 src/dpdk/drivers/net/ $ cd linux_dpdk $ ./b configure $ ./b build $ cd ../linux $ ./b configure $ ./b build
ビルドできたら
ビルドに成功したら、 trex-core ディレクトリ配下にscriptsというディレクトリができると思います。scripts配下ではリリースされたものと同じようなことができます。
$ cd /opt/trex-core/scripts $ ./t-rex-64 -i
T-Rex自体の動作確認などは、以下のページなどを参考に動作確認を実施してみると良いと思います。